In 2013 I wrote a technical blog post for work. Since then the company was purchased by Micro Focus and the post has disappeared (probably due to branding issues). I’m re-posting it here (with minor changes) for future reference. Opinions expressed here are my own and do not represent those of Micro Focus or its entities.
The terms QTP (QuickTest Professional) and UFT are used interchangeably.
The meaning of the following script line should be obvious to anyone using UFT:
Browser("B").Page("P").Link("L").Click
It says “Click link ‘L’ on page ‘P’ of the browser ‘B’. But are things really that simple? Let’s drill down into each part of this step in order to understand why UFT’s designers chose to represent objects in this specific way.
Objectives of the Object Model
When deciding how to represent an object in an Application Under Test (AUT) several considerations are taken into account:
- Robustness – A test should fail only if there is something wrong with the functionality of the AUT. Changes with no functional effects (e.g. font change) should not affect the test outcome.
- Maintainability – If the AUT changes in a way that affects the test it should be easy to update the test in order to accommodate the changes in the AUT. This consideration gives rise to sub-considerations:
- Readability -It should be obvious what a test does by reading it
- Organization – Objects in the object repository should be organized in a logical manner so that it will be easy to find an object when looking for it.
Browser
What is a Browser?
Today, a Browser is a tab. But before tabs were introduced, a browser was a software application used to access the World Wide Web. The object hierarchy was very simple:
Browser("B").Page("P")
With the advent of tabbed browsers, we had to decide how QTP should represent a tab. The naïve answer would be to just add another level to the object hierarchy:
Browser("B").Tab("T").Page("P")
But this has the following drawbacks:
- Tests created on a tabbed browser will not work with a non-tabbed browser (even if only one tab is ever used)
- Placing the tab under a specific browser is rarely a functional issue, as it breaks the robustness objective we discussed at the beginning of this article. A web page should be rendered identically whether it is created in a separate top-level window or as another tab
The drawbacks to having the Browser object represent a specific tab were mostly esthetic, but it was still the best option.
Because there may be some functional significance to having separate tabs in the same browser, we added the OpenNewTab, IsSiblingTab and CloseAllTab methods to the Browser test object. I’d like to know if anyone actually uses them… please leave me a comment below to let us know if you do.
Nowadays, tabs can be ‘torn off’ from one browser instance and onto another. So it seems clear that we made the correct decision.
Note: A minor compatibility issue that arose from this was that the window handle (HWND) for the Browser no longer refers to the top-level window. Creating a regular Window test object with this HWND won’t allow you to call the Minimize or Move methods, or indeed call any other method which is available in Window but not in Browser.
A Browser’s ‘Description’
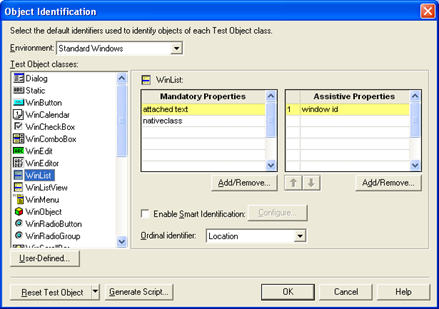
The object identification dialog doesn’t list properties for a browser’s description. This means that if more than one browser is open, the description will use an ordinal identifier, by default, creation time:
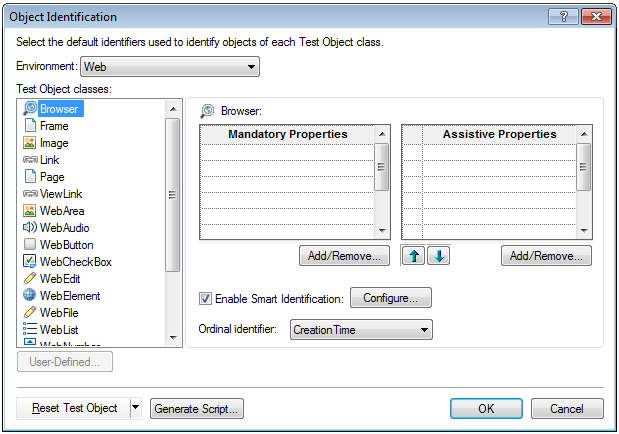
There isn’t actually a generic way to distinguish between browsers. Let’s say you open a browser on your homepage, navigate to your mail account to see what’s new, hang out in Facebook, and then navigate to your business application and start running tests. If UFT used title as a default description property, the object repository would have many browser test objects – one for the homepage, one for mail, one for Facebook, etc. – and it would be very hard to find the correct browser. This breaks the organization principle discussed earlier.
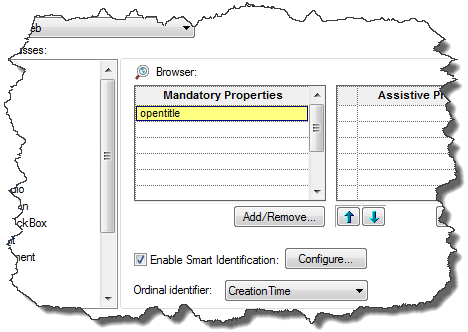
But if there is a consistent pattern to how you use your browsers, you can create a more robust description by using the opentitle, openurl or openedbytestingtool properties. For example, this screenshot shows how to use opentitle for all new browser objects, in the Object Identification dialog:
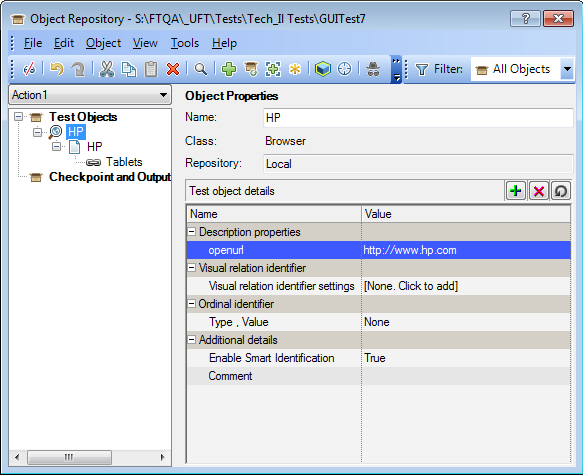
This screenshot shows how to use openurl for a specific browser:
And the following line of script shows how you can use descriptive programming to refresh a browser by its openurl property:
Browser("openurl:=http://www.hp.com").Refresh
Page
The Page object represents the top-level HTML document displayed in the current Browser. Since there can be only one top-level HTML document each Browser will have only one page. So why do we need another layer in the hierarchy? Why not just make the Browser object represent the top-level HTML document as well as the tab window?
The answer is to preserve the test maintainability objective we described earlier. We determined that we don’t want to create a new Browser test object whenever the HTML being displayed changes, but this may lead to having tests with many dozens (hundreds?) of test objects under the Browser. In order to prevent this, we create an artificial split so that the controls that appear under the same Page test object logically belong together.
Thus if you have a login page and an accounts page you can find the username edit field without sifting through all the test objects that appear in the accounts page, because the appropriate controls are grouped logically.
Tip: You can modify the amount of page test objects created in UFT in Options > Web > Page/Frame Options
Frame
A Frame object represents an HTML document under the main object (inside a FRAMESET or IFRAME). There’s nothing particularly interesting about this, so let’s move on…
WebElement(s)
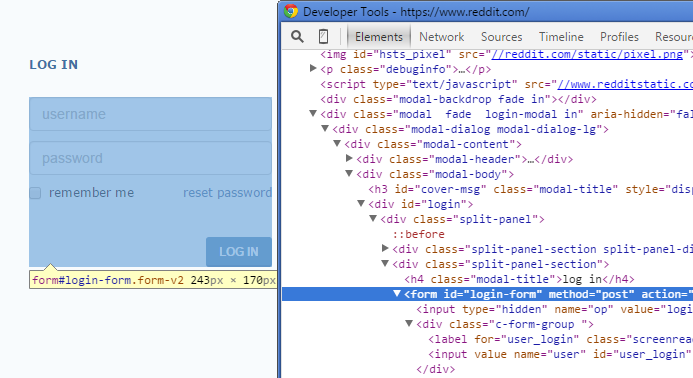
Under the Frame (or Page) object, all the web test objects (Link, WebButton etc.) are siblings. But this isn’t how they appear in the actual HTML – the actual elements in an HTML document are typically nested in a deep hierarchy:
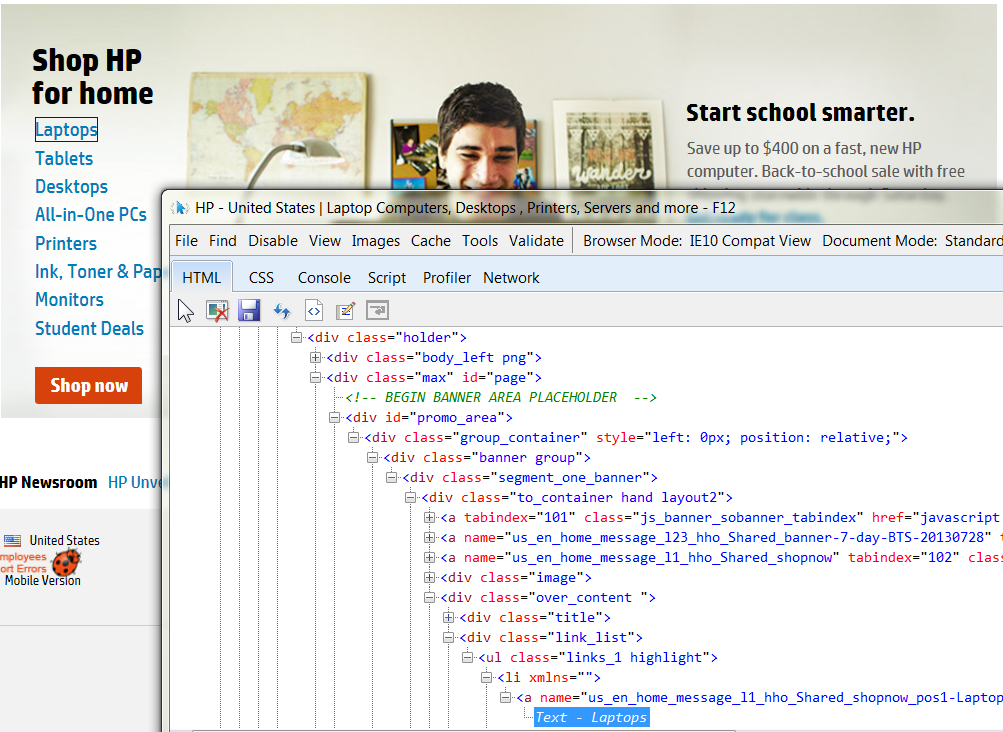
A typical web hierarchy as viewed with IE’s developer tools
Not only would adding all parent elements to the test make the test unreadable, it would also mean that the test will fail for every minor change in the HTML, and break our readability and robustness objectives respectively.
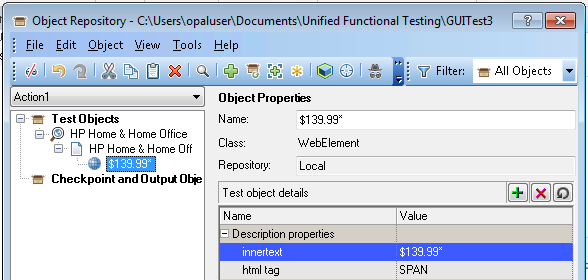
Although UFT flattens out the hierarchy when recording or learning an object, you can still create a hierarchy by yourself. If you drag a WebCheckBox (or any other object) under a WebElement in the Object Repository (or just nest them using descriptive programming) UFT will only look for the checkbox under its parent test object. This means that the description you give for the WebCheckBox only has to achieve uniqueness relative to its container, which can simplify things immensely for applications that contain many similar elements (such as the Add to cart link on an online store). For example, the following screenshot shows how the HP Slate 7’s ‘Add to cart’ link on HP’s online store appears in the Object Repository Manager. It is directly underneath the ‘Slate | HP Official Store’ page (other test objects were removed for clarity in the screenshot):
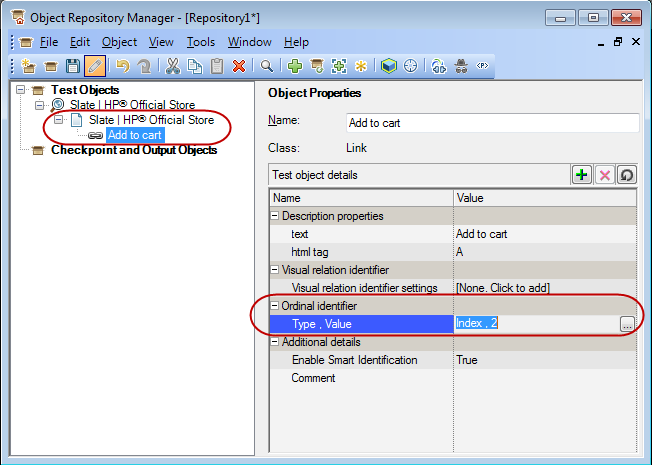
The ‘Add to cart’ link appears many times on the page, since there are many items which can be purchased. This specific one is the third one (ie. having an index of 2) on the page. UFT will have to find the first two links until it can locate the third one
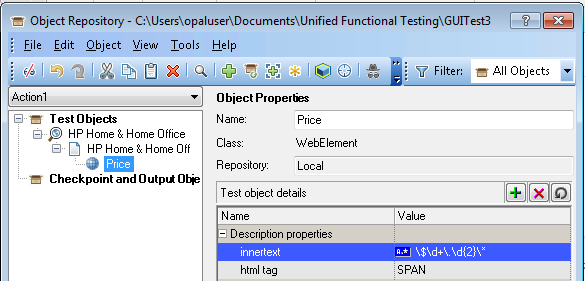
We can simplify it by adding the context element of HP Slate 7 to the hierarchy. In this way, UFT only needs to locate the HP Slate 7, and then find the only ‘Add to cart’ link in the context of the HP Slate 7. Since there’s only one link, we don’t even need the ordinal identifier:
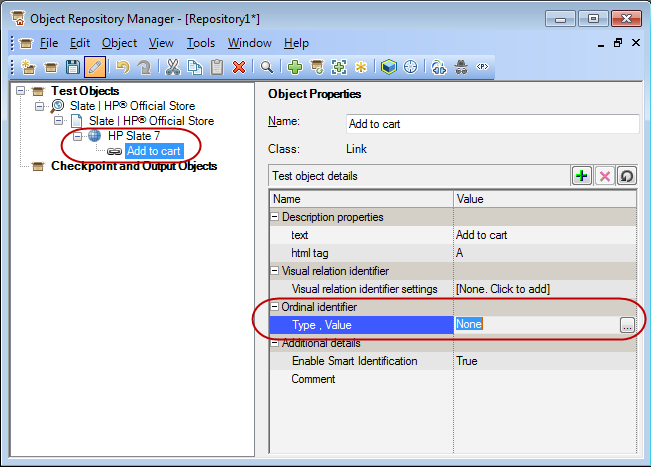
HTML Tag
By default, UFT uses the html tag property as part of the description of all web test objects, even those for which it’s pretty obvious what the tag name will be.
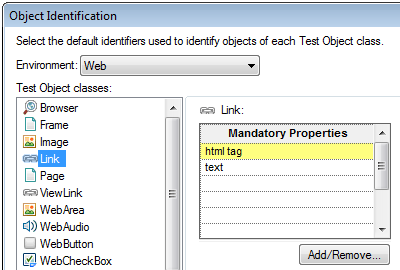
The reason for this is that in order to identify a test object UFT must check all the elements on the page to see whether they fit the description, and this can be slow for big pages with thousands of element. But browsers support getting the elements of a specific tag, and if UFT can use this function it can perform the search on far fewer elements. Because the html tag is part of the description by default you don’t usually have to think about it. But if you change an object’s description (in the object repository or in the object identification dialog) you should keep this in mind. If you use descriptive programming and you’re seeing that performance is a bit slow, consider adding the html tag to the description.
Note to WebExtensibility authors: Consider adding the html tag property to the description of new types.
In Conclusion
I hope that after reading this post you have a better understanding of why UFT represents controls the way it does (at least in the Web addin). Some things that might have seemed arbitrary should now make some sense. You may have even picked up a tip or two that will help you improve your web tests!